Don't like this style? Click here to change it! blue.css
LOGIN:
Welcome .... Click here to logout
Class 2: Proper Password Storage
Overview: This lesson will walk you through some best practices for storing user passwords. While that alone might be exciting enough the real aim at this stage is to show you how to handle string encryption. That is, even if you assume that your hash algorithm is extremely powerful you must use it carefully. The ability to ballpark the cost of the brute force attacks against your scheme is one of the most valuable lessons in early crypto (or any computational endeavor).
The Password Storage Problem
As a cryptographer you should learn to be paranoid. If you have to validate users (and you probably will have to one day) then you might end up needed to confirm their password. Imagine that you store the password in plaintext in a database or on your server somewhere. Then anyone that gets access to that file/database/server can read that user's password and go try it on all other platforms.
So the first rule of password storage is to NEVER STORE PLAINTEXT PASSWORDS.
Well this is where the Hash function comes into play. If we hash the password and store the hexdigest then a leak of that database doesn't give away the users' passwords.
We also saw that if the user picks a stupid password then even a hash isn't good enough to keep a brute-force attack away. So we will learn to also SALT AND STRETCH passwords (more on that soon).
We now have the top goal of this lesson: learn how to store a password securely. But more important is learning how to reason about the difficulty of an attacker overcoming your defenses. With that comes developing a proper level of paranoia and understanding of the power of modern computers.
Message Space
Overview: The big idea of this part is to get you thinking about an encryption in terms of all possible inputs and all possible outputs. If you are only sending one of two messages but you send them over and over again (e.g. a series of "yes" or "no" messages ) then we need to think carefully about how to artificially increase that input "space of possible messages" so that an attacker can't just try them all and see which one matches. We're also giving you a rough estimate for how secure a scheme is based on the size of this search space.
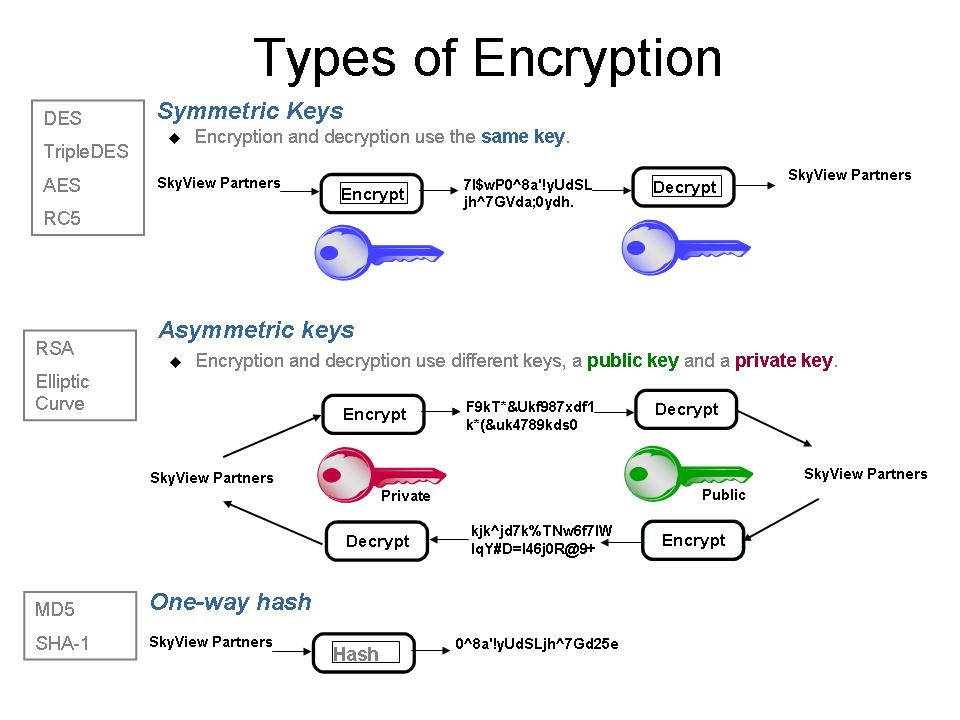
Encryption ciphers are "keyed"-functions. They consume a message, a secret key and they produce a cipher text. We'll deal with this in more detail in future chapters. The important thing to recognize is that if you are hiding the meaning of a message so that someone else (even yourself later) can read it only if you let them then there are TWO INPUTS, the message, and a secret key that you share with whoever is going to read your encryption.
In the last lesson we used the very best hashing algorithm available to "one-way encrypt" our message and yet it still crumbled to a little bit of Python. The reason is that the number of possible inputs into the function was not large enough.
I'm going to use the term message space to mean the set of all possible messages that might have produced a given encryption. In our case the message space was words from the dictionary which means the message space had a size of about 200,000 possible messages.
We'll be doing a lot more encrypting as we go and discussing this in a lot more detail. For now, I just want to highlight that there are actually three "spaces" involved with any encryption. The message space (all possible plaintext inputs), the key space (all possible secret keys), and the cipher space (all possible output encrypted texts). It's a little but fuzzy to correctly decide how big each of these spaces is, but knowing each is essential to estimating the security of an encryption scheme.
Now, in the case of hashing algorithms there are NO SECRET KEYS. What that means is that every time I hash the word "banana" I get the same output from SHA512 (a different but still repeatable output if I change the algorithm to SHA256). Whereas with a keyed-encryption I could encrypt "banana" with the secret key "sundae" and get one encryption, but "banana" with secret key "sunday" will give me a different encrypted text.
Typically with cryptographic hashes the size of the cipher space is the number that matters the most for security. Because an attacker that can find a second input that matches the hash of your password can pretend to be you. But in our program from the last lesson we exploited the fact that the number of inputs was too small. That is the message space was too small.
When analyzing a brute force attack we need to estimate the number of inputs (secret keys or messages) that have to be checked to reverse the output.
In the case of a Hash function there is no secret key. Everyone needs to be able to verify that the same string hashes to the same value. So a brute-force attack on a hash function requires trying every considered input, while a brute force decryption requires trying every possible key.
Anyhow our message space yesterday was about \(2^{18}\) items. For your estimation purposes when it comes to brute-force attacks the following helps you ballpark the amount of security you get for various size problems:
A key space/message space of \(2^{64}\) is enough for a couple hours of security
A key space/message space of \(2^{128}\) is enough for several decades of pre-quantum security
A key space/message space of \(2^{256}\) is enough for several decades of post-quantum security
Message Space: Estimate the size of the message space for 2 word phrases, 3 words phrases, 4 word phrases, and 5 word phrases. (Again, concatenate the words separate by spaces.)
Cost of breaking: If you estimate the cost of a core-hour of Amazon Web Services at a half penny (under the true cost IMHO), then what is the cost of reversing the password hash above for 1-5 words? Use the ballpark execution times from lesson 1. (Answers hidden in this HTML source code, only look when you've really tried.)
The number of hashes possible per second is around 2 million (we needed a tenth of a second to hash 200000 words). So the cost of busting a 1 word hash is tiny (1/72000 of a penny). The number of 2 words combinations is (2*10^5)^2 which is 4*10^(10), divide that by the hashes per second of 2 million and get around 20000 seconds which is 5 and a half hours, that costs us 2 cents. The number of 3 word combinations gets us to (2*10^5)^3 which is 8*(10^(15)), divided by 2*10^6 we get 4 billion seconds which is about 126 years of computation time. Now core-years are not too expensive actually, since one core-hour is half a penny we can do 200 hours for a dollar and this whole thing costs between 5 and 8 thousand dollars to break. Now four words will be around 5 and a half million, and five words will be around a trillion dollars.
Overview: In this part we introduce you to two practical ideas that are needed when storing passwords. Cryptographic hashing to minimize readability and salting to prevent hackers from gaining the economies of scale.
Why we hash passwords.
In lesson 1 we learned a little bit about hashing and how to call SHA-512. Let's now look at the first place most developers need to pull out hashing: storing passwords.
Constraint 1: We don't store plaintext passwords. It asks the user to trust us too much. What if the database is accessed? What if a disgruntled coder wants to stalk an ex? etc. etc. If you think it's too paranoid (you can never be too paranoid in this field) just imagine any one of the big headline hacks of the last couple of years. In many of those cases passwords were stored in plaintext. In each of those cases a single breach led to a massive problem (and stock prices dropping and jobs lost, etc. etc.).
Constraint 2: We have to be able to confirm that a user is who they say they are. Otherwise what's the point of a password? So if we store a hash digest of a password then when that user logs in we must hash their password again and now we can check that it matches the hash in our records.
How to salt passwords and why.
The idea of salting a hash is to add/concatenate a random chunk of bits to the end of the password before hashing. Then save (in the same database row that stores the hash) that random chunk of bits along with the hashed password.
The reason this helps is that the attacker of your scheme can't scale their attack to many users or many systems (or the whole internet). A rainbow attack is one in which the hashes of passwords are computed ahead of time. Now the attacker can just use a table to find the original password. Salting means that a rainbow attack has to be recomputed for each individual user. That makes an attacker spend a lot more money per user, which is the way I tend to analyze security.
Google as rainbow attack: Please use a search engine to tell me what password was used to generate the hash: b9c950640e1b3740e98acb93e669c65766f6670dd1609ba91ff41052ba48c6f3 password1234. How many results did it generate?
That task shows you, by way of google, that hashing is not enough. Here I take a weak password and hash it using SHA256. Next I will add a keyboard cat salt to the end and hash that. Now the next task should convince you that salting helps protect your users from themselves (at least a little).
Verify no results: Now how many results does a search for 176132e077f7e59d9e648034e9b368a84a98e6c24973c58772960ce293bec39d generate?
Practice generating and using a salt:
Advice: In practice use a well randomized 256-bit salt.
We will use an easy to install Python library to generate a strong salt that you can repeat for every different user you need to authenticate. Do this once every time you store a new password.
Off-the-shelf salting: In a c9 instance install the Python module bcrypt with the following line of sudo pip install bcrypt .
Generate a decent salt: In ipython call import bcrypt followed by bcrypt.gensalt() .
Kata: Salt and Hash a passphrase
Create salted hash: Now write a function which consumes a salt and a password and computes the SHA256 hash of the password concatenated with the salt. (If you're new to Python functions use my above screenshot for guidance.) Exchange a sample password/salt pair and the resulting hash with a partner and confirm that you each compute the same thing. (Give them the plaintext password, the salt you used, and the final hex digest and vice-versa. Validate that it is repeatable and correct.)
Overview: This is one of the coolest parts of Module 1. It is a simple trick that lets you make your hash function take arbitrarily long to compute. That means that you can change the math on your attackers. Instead of 2 million hashes per CPU-second it can be 1 hash per CPU second, or even a fraction of a hash per second. So now you are in control of setting how hard it is for an attacker to break you.
Now we will apply some asymptotic leverage to this situation by "stretching" the passwords. We will cobble together a more super-powered hashing scheme by repeating the hash over and over again.
Here is the pseudo-code (page 304 of our Crypto Engineering book):
$$ x_0 := 0 $$
for \(r\) iterations: $$ x_i := h(x_{i-1} \parallel p \parallel s) $$
$$ K := x_r $$
Here the \( \parallel \) notation means concatenate as strings.
That notation is particularly mathy, so it might seem too intense. That is a knee-jerk reaction from math-anxiety. It's just different and you can treat it like learning the rules to baseball. Here is my simpler explanation:
\(x_0 := 0\) means set a variable \(x_0\) to 0, the \(:=\) notation is assignment, so if I wanted to set \(w\) to 23 I could write \(w := 23\) and you would read it more like a command than an observation.
Then the \(r\) iterations. This is saying that we want to loop over many hashes. Let me show you by example:
If \(x_0 :=\) "0" then \(x_1\) will be the hash of "\(0pass1234SALTHERE\)". Suppose that the hash of that is "\(abcd\)" (it wouldn't be of course but we're explaining here). Then \(x_2\) would be the hash of "\(abcdpass1234SALTHERE\)" and so on and so on and so on.
Picking an r: The more often you iterate this process the more expensive it is to do a single hash. So for instance with \(r\) around 1 million we just increased the brute-force reverse cost to 1 core year even with just 2 random words. The cost of doing the hashing should be as large as our user can stand, normally this about 1 second.
Kata: Salt and stretch a passphrase with specified stretch factor
Test this out: Alter the code from the last part to take in a third parameter r which is the number of stretches we do. Hand compute the result for a specific password and salt when r=3 then make sure your function's output matches (even the screenshot I have above this task).
An ASIDE on hex and cryptography
Please be aware that when we share a hex digest like "30fcc3f7a0844d8071bd584c3ad74e367f9d3e5ba7ab989883c6127c4db19504" that it is not copy paste-able into code. What we are really after in crypto is random looking 1s and 0s. That hexdigest is made to be shareable between humans, the actual content would be seen as: 0\xfc\xc3\xf7\xa0\x84M\x80q\xbdXL:\xd7N6\x7f\x9d>[\xa7\xab\x98\x98\x83\xc6\x12|M\xb1\x95\x04 which is 32 characters long. The hex digest "30fcc..." is 64 characters long. The idea is that "30" is really "0x30" which is the single byte character "0" in ASCII and not all ASCII characters are printable, when that happens we write "\xa7" which is one character not many.
ASCII hex vs real hex Execute the following Python snippet which looks at the binary digits of a hexdigest and the binary digits of a raw digest. Look at the results and decide if you can tell which one is closer to a random coin flip at each bit.
REST OF CLASS WARNING: if ever you are really really stuck consider if you are trying to use a hexdigest as ASCII instead of as raw bytes. It just won't work if you mix methods.
Kata: Learn to convert freely between hexdigest and raw data.
Conversion: Compute a SHA256 hexdigest by hashing any phrase (e.g. "I rule"). Now convert that string from "562877fbc677d2" style to raw characters like "V(w\xfb\xc6w\xd2" and back (use binascii).
Overview: In this part we put it all together with a series of challenges that allows you to end up with a program that makes a hash that is salted well and stretched long enough to take 1 second. As time goes on and CPUs get stronger that means this program will stretch longer and longer so that adversaries are always at the same disadvantage. Good luck!
Now try to make this scheme a reality in these steps:
In the last part you wrote a function that can:
Consume a password
Compute or consume a salt
Consume an r (the number of iterations of stretching)
Produce a stretched and salted password / digest
Kata: Use timing to analyze a program. Have a program adapt itself.
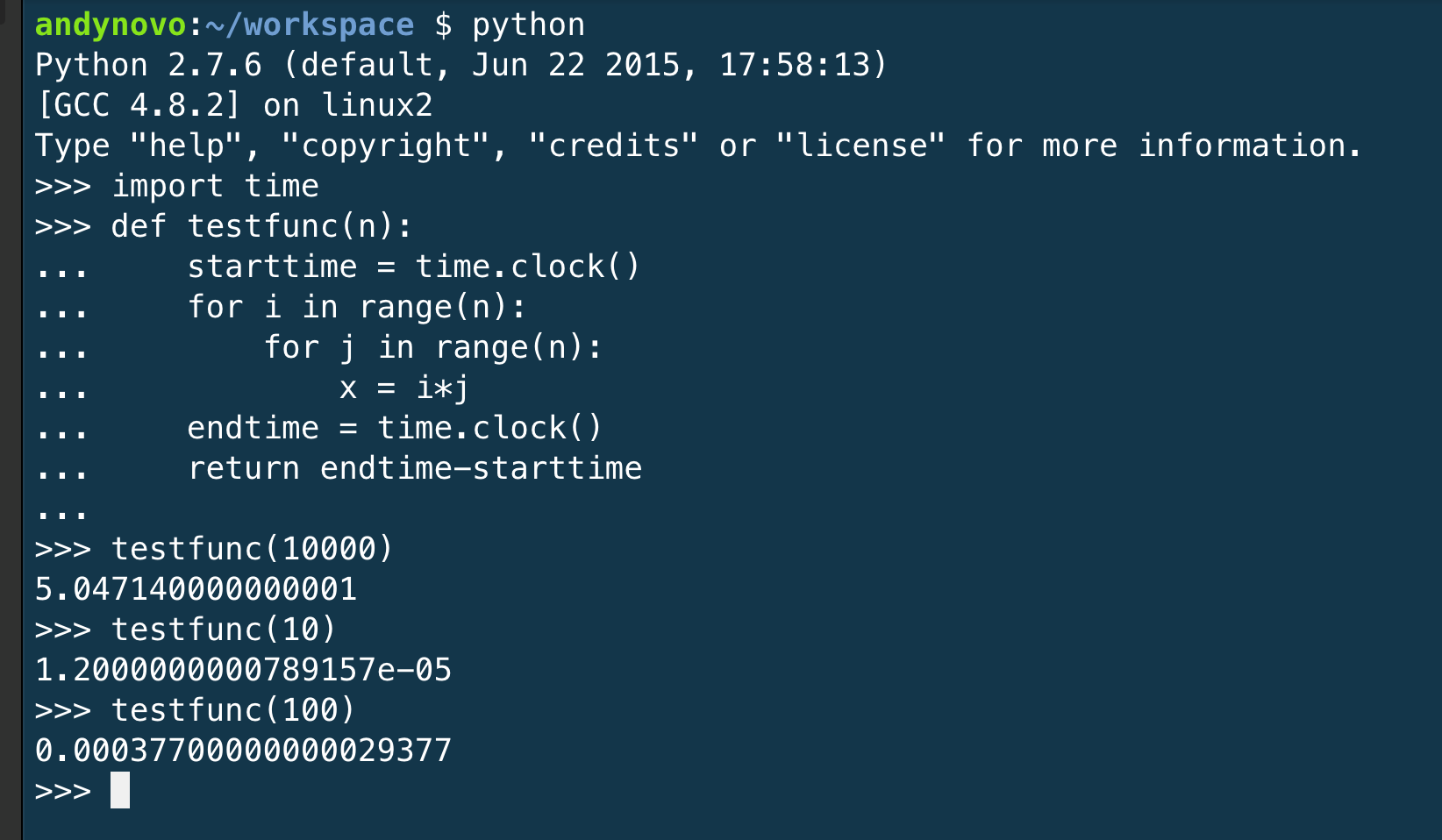
Time it Use the time module or some timing mechanism (example follows) find an \(r\) which causes your hash function to take 1 second.
Here is an example of timing a function:
Put it all together: Now use timing and some guessing to make a function which consumes just a password and returns a (salt, r, theHash) triplet that took around 1 second to create. Verify that you can recreate theHash.
Intellectual Challenge : Compute an r such that a single common word from the dictionary is enough that it takes 1 core-year to brute-force reverse this hash scheme. How long would it take for your user to compute a single hash?